AI Issues: SpikingBrain AI Model Released

Image source: ChatGPT-5
A New Advance in Brain-Inspired AI
Key Points
- SpikingBrain 1.0 mimics how the human brain processes information. It uses spiking neurons that activate only when needed, making it more efficient.
- Researchers trained 7B and 76B parameter models using less than 2% of the data used in conventional AI systems.
- The 7B model processed 4-million-token prompts at 100x faster speed than typical models.
- Both models were trained and tested entirely on MetaX GPUs, demonstrating that China can build advanced AI without NVIDIA.
- A public demo called "Shunxi" lets anyone try the SpikingBrain model online.
SpikingBrain: A New Brain-Inspired Alternative Model
A research team in Beijing unveiled SpikingBrain 1.0, an AI system designed to more closely mimic how the human brain works.
Unlike today's large language models (LLMs) that keep all neurons in an "always on" state, SpikingBrain neurons activate only when necessary.
This approach, combined with hybrid attention mechanisms and Mixture of Experts (MoE) scaling, makes the system much faster and more efficient.
The researchers say that at a time when cost, data, and hardware availability are critical concerns, this represents a new direction for large language models.
Training Shows Faster Speed with Less Data
SpikingBrain comes in two versions.
The smaller SpikingBrain-7B designed for efficiency, and the larger SpikingBrain-76B built for improved accuracy.
Both models were trained on approximately 150 billion tokens — less than 2% of the data typically used for modern language models.
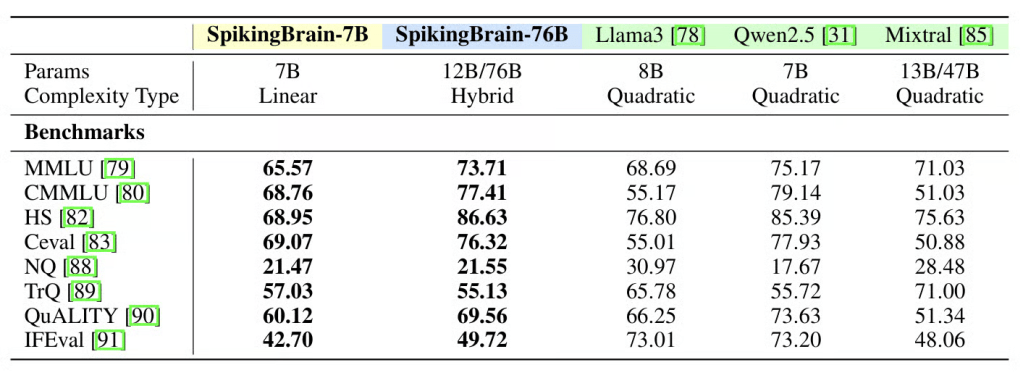
Despite this much lighter training load, both models matched or outperformed many existing systems in evaluations.
SpikingBrain-7B is the efficiency-focused model.
It activates fewer parameters per token, making it particularly well-suited for tasks with very long inputs.
Test results show it processed 4-million-token prompts over 100x faster than typical transformer models while maintaining stability over weeks.
On benchmarks like MMLU, CMMLU, ARC-C, HellaSwag, and C-Eval, the 7B model recovered approximately 90% of baseline transformer performance while using only a fraction of the training data.

The larger SpikingBrain-76B uses a hybrid Mixture of Experts architecture, increasing complexity while continuing to improve accuracy.
This model significantly narrowed the gap with top transformer models and in some cases matched or surpassed widely used systems like Llama2-70B, Mixtral-8x7B, and Gemma2-27B.

SpikingBrain Performance and Efficiency in Numbers
- 150 billion tokens — training data used for both models, less than 2% of typical modern LLM datasets.
- 100x faster speed — time to first token on 4-million-token prompts was 100x faster with SpikingBrain-7B.
- 90% benchmark recovery — the 7B model reached ~90% of baseline transformer performance on MMLU, CMMLU, ARC-C, HellaSwag, and C-Eval.
- Hundreds of MetaX C550 GPUs — hardware used for training, demonstrating large-scale stability outside the NVIDIA ecosystem.
Hardware Independence: A System Running on MetaX Chips
One of the most notable achievements is that researchers trained SpikingBrain exclusively on hundreds of Chinese MetaX C550 GPUs, not NVIDIA hardware.
To achieve this, the research team customized operator libraries, parallelization strategies, and memory optimizations for MetaX.
The team reported stable large-scale training over several weeks, emphasizing that advanced large language models can now be built and deployed outside the NVIDIA ecosystem.
This independence is particularly significant given ongoing concerns about chip supply chains and national technology independence.
Shunxi Demo Available for General Users
To showcase their progress, the researchers open-sourced the smaller SpikingBrain-7B model through GitHub.
This gives developers and researchers the opportunity to study the system and build upon its efficiency-focused design.
They also introduced Shunxi, a public demo of the flagship SpikingBrain-76B, to demonstrate the capabilities of the larger system.
Unlike the 7B release, Shunxi is not open source but offers an online trial where users can experience the model's performance firsthand.
The research paper mentions the demo's availability but does not provide a permanent link.
The model demonstrates not only SpikingBrain's performance but also its ability to run entirely on domestic infrastructure.
Learn More About SpikingBrain
Q: What makes SpikingBrain different from other AI models?
It uses spiking neurons that activate only when needed, similar to how the human brain works, making it faster and more efficient.
Q: How much training data was used?
Approximately 150 billion tokens, less than 2% of what most large models require.
Q: How fast is it compared to existing AI systems?
The smaller 7B model processed 4-million-token prompts at 100x the speed of typical systems.
Q: What hardware does it run on?
It was trained and tested entirely on Chinese MetaX GPUs without using NVIDIA chips.
Q: Can the general public try SpikingBrain?
Yes. The smaller SpikingBrain-7B is available as open source on GitHub.
For the larger SpikingBrain-76B, the team launched a public demo called Shunxi.
The research paper confirms availability but does not provide a permanent link.
Implications
The release of SpikingBrain highlights three important shifts:
Efficiency over scale
Brain-inspired design shows that performance improvements don't always require bigger datasets or higher costs.
Hardware diversification is underway
By proving MetaX GPUs can run advanced models, China is reducing its dependence on Western chip manufacturers.
Global competition is intensifying
As multiple countries build their own AI systems and hardware, the landscape is becoming more diverse and competitive.
These new developments promise faster, cheaper, and more energy-efficient systems, reshaping how and where large language models are built.
IMPAKERS Blog | Microsoft Office 365 Claude Sonnet 4 Integration Announced? Read more
Source: Alicia Shapiro, AiNews, "China's New SpikingBrain AI Models Deliver Speed and Efficiency on Domestic Chips", https://www.ainews.com/p/china-s-new-spikingbrain-ai-models-deliver-speed-and-efficiency-on-domestic-chips, (2025-09-15)