AI Issue: New OpenAI Model GPT-OSS

OpenAI Launches GPT-OSS-120B and GPT-OSS-20B as Open-Weight Language Models
Key Highlights
- OpenAI has released two new open-weight language models, GPT-OSS-120B and GPT-OSS-20B, available under the Apache 2.0 license.
- These models match or outperform proprietary systems like GPT-4o, o3-mini, and o4-mini on benchmarks such as HealthBench, AIME, and TauBench.
- GPT-OSS-120B runs on a single 80GB GPU, while the smaller GPT-OSS-20B operates on edge devices with just 16GB of memory.
- The models support tool use, Chain-of-Thought (CoT) reasoning, structured outputs, and adjustable reasoning effort for latency-performance tradeoffs.
- OpenAI conducted extensive safety evaluations including independent expert reviews and fine-tuning according to the Preparedness Framework.
OpenAI Releases GPT-OSS Models to Advance Open AI Development
Something truly important has happened at OpenAI.
They've released two new open-weight language models, GPT-OSS-120B and GPT-OSS-20B, available for anyone to use under the Apache 2.0 license.
These models are specialized for reasoning tasks, tool use, and cost-efficient deployment.
They're specifically built to run well on consumer hardware, are fully customizable, and support structured outputs.
GPT-OSS-120B delivers near-o4-mini level performance on reasoning benchmarks while operating on a single 80GB GPU.
GPT-OSS-20B achieves results comparable to o3-mini while requiring only 16GB of memory, making it perfect for on-device or local inference.
These models outperformed other open systems on complex tasks.
GPT-OSS-120B particularly excels in tool use, function calling, and Chain-of-Thought (CoT) reasoning.
On the HealthBench metric, it even surpassed proprietary models like o1 and GPT-4o.
Furthermore, it integrates seamlessly with OpenAI's Responses API and supports agentic workflows with outstanding instruction following.
Reasoning intensity can also be adjusted according to latency requirements.
Model Architecture and Performance
OpenAI trained the GPT-OSS models using state-of-the-art pre-training and post-training techniques, focusing on reasoning, efficiency, and practical usefulness across diverse deployment environments.
While they had previously open-sourced models like Whisper and CLIP, this is the first open-weight language model developed since GPT-2.
Each model uses a Transformer architecture with a Mixture-of-Experts (MoE) design that activates only a fraction of parameters per token to improve efficiency.
| Model | Total Parameters | Active Parameters | Layers | Experts | Active Experts | Context Length |
|---|---|---|---|---|---|---|
| GPT-OSS-120B | 117B | 5.1B | 36 | 128 | 4 | 128k |
| GPT-OSS-20B | 21B | 3.6B | 24 | 32 | 4 | 128k |
To further improve inference and memory efficiency, both models alternate between high-density and local banded sparse attention patterns (similar to GPT-3) and grouped multi-query attention patterns with a group size of 8.
Rotary Position Embeddings (RoPE) are used for positional encoding.
These models support a maximum context length of 128,000 tokens.
They were trained on a primarily English, text-only dataset with strong representation across STEM, coding, and general knowledge.
Tokenization was performed using a new o200k_harmony tokenizer that is being open-sourced alongside this release.
Detailed information can be found in the model cards.
Post-Training and Reasoning Control
Post-training followed the same methods used for OpenAI's o4-mini, including supervised fine-tuning and reinforcement learning (RL) stages.
The models are aligned to OpenAI's Model Specification, supporting chain-of-thought reasoning, tool use, and instruction following.
By applying the same techniques used in OpenAI's state-of-the-art proprietary reasoning models, the GPT-OSS models demonstrate strong post-training performance across reasoning tasks.
Like OpenAI's proprietary o-series, these models offer low, medium, and high reasoning modes.
This allows developers to optimize for latency or performance by adjusting the system message parameter.
Test Results
GPT-OSS-120B and GPT-OSS-20B were tested on standard academic benchmarks to evaluate coding, competitive math, health-related reasoning, and agentic tool-use capabilities.
In these evaluations, the models consistently matched or exceeded OpenAI's proprietary reasoning models, including o3, o3-mini, and o4-mini.
Codeforces (Competitive Coding):
GPT-OSS-120B achieved a higher Elo rating than o3-mini and performed comparably to o4-mini, demonstrating strong results in competitive programming tasks.
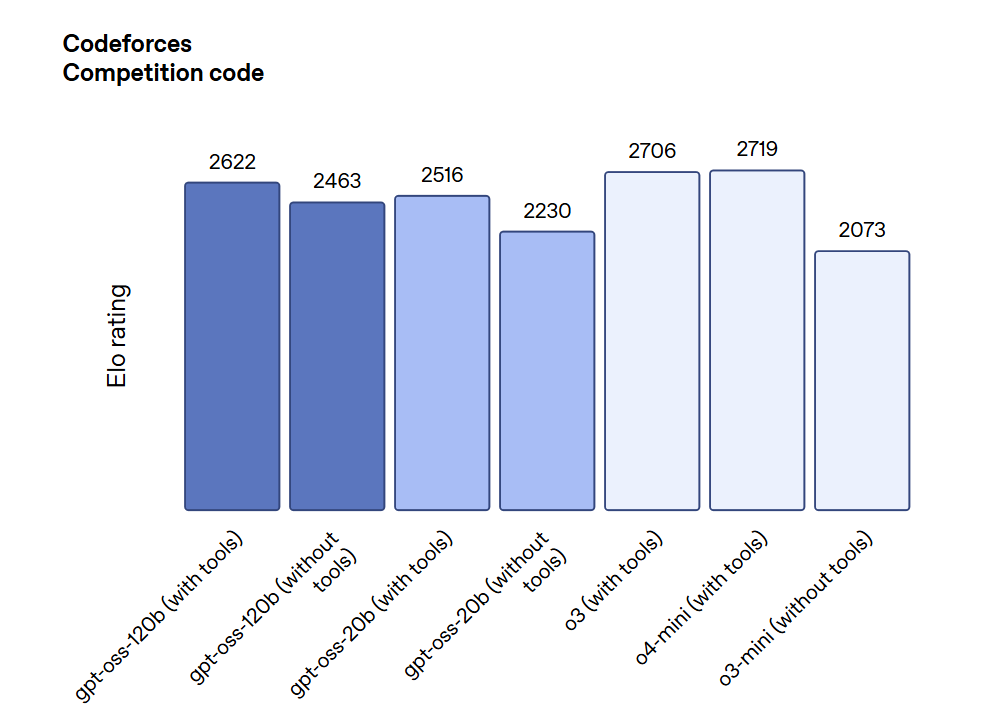
Image source: OpenAI
Expert-Level Problems Across Multiple Domains:
On this benchmark that tests reasoning abilities across various expert-level academic domains, GPT-OSS-120B and GPT-OSS-20B showed competitive performance, especially in tool-assisted scenarios.
While proprietary models like o4-mini lead in this area, the GPT-OSS models still delivered meaningful results on highly specialized prompts, demonstrating broad applicability.
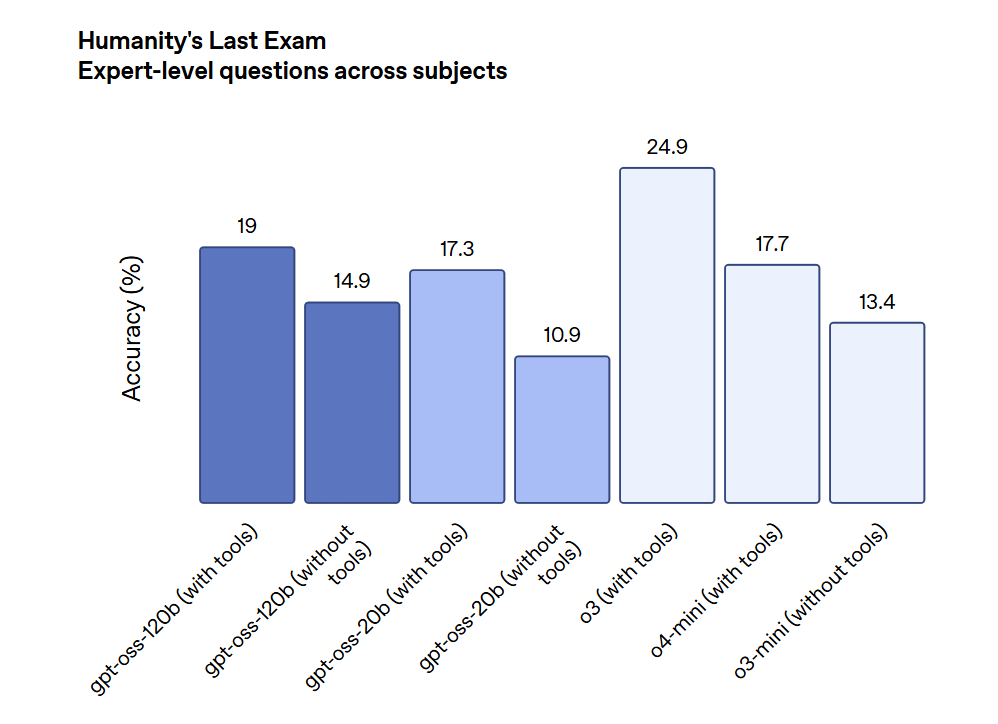
Image source: OpenAI
Health & Medical Conversations:
In both standard and hard evaluations, GPT-OSS-120B and GPT-OSS-20B outperformed GPT-4o, o3, and o3-mini, showing particular strength in health-related reasoning benchmarks.

Image source: OpenAI
AIME 2024 and 2025 (Competitive Math):
Both models achieved high accuracy, with GPT-OSS-120B scoring 97.9% and GPT-OSS-20B scoring 98.7% on AIME 2024.
On AIME 2025, both models outperformed o3-mini, and GPT-OSS-20B surpassed o3 on certain tasks despite its smaller size.
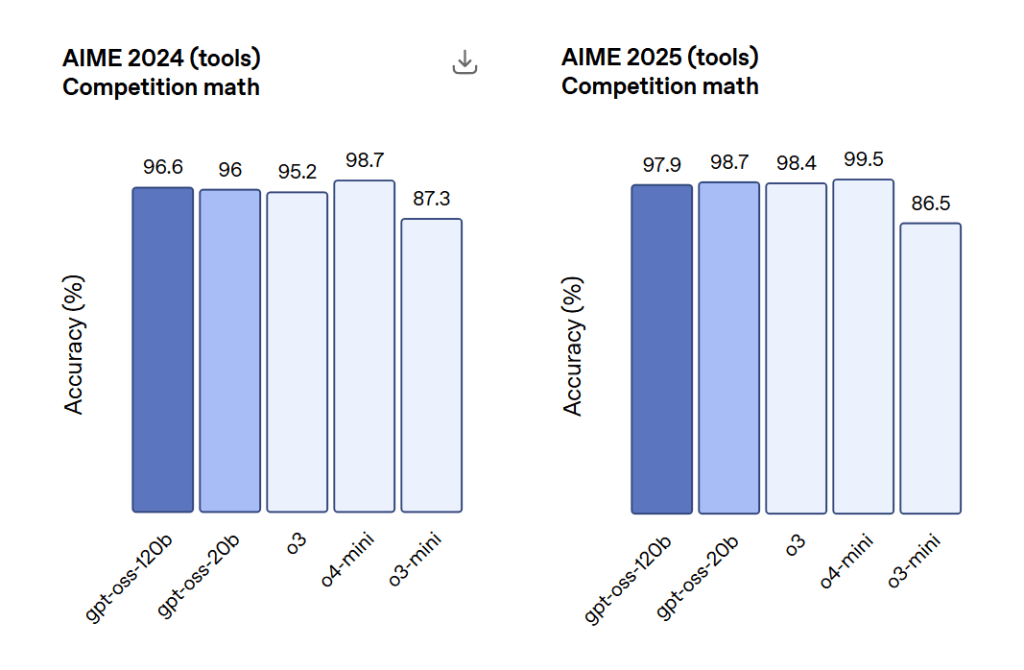
Image source: OpenAI
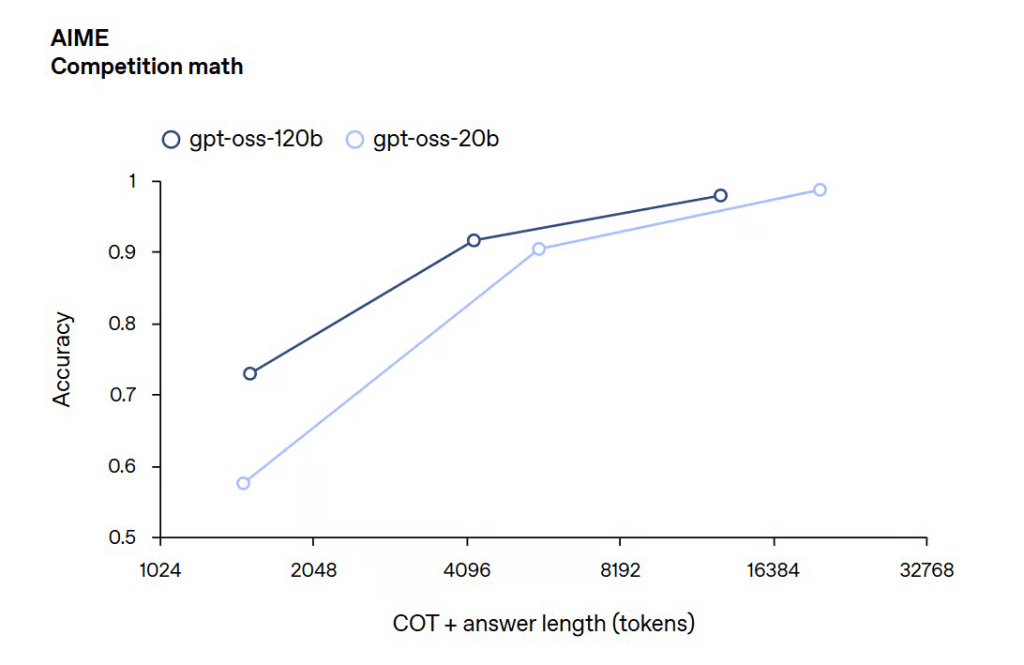
Image source: OpenAI
Tau-Bench (Tool Use and Function Calling):
The models demonstrated strong performance in few-shot function calling, long-answer generation, and Chain-of-Thought (CoT) reasoning, closely tracking the accuracy of o4-mini and o3 across tool-augmented evaluations.
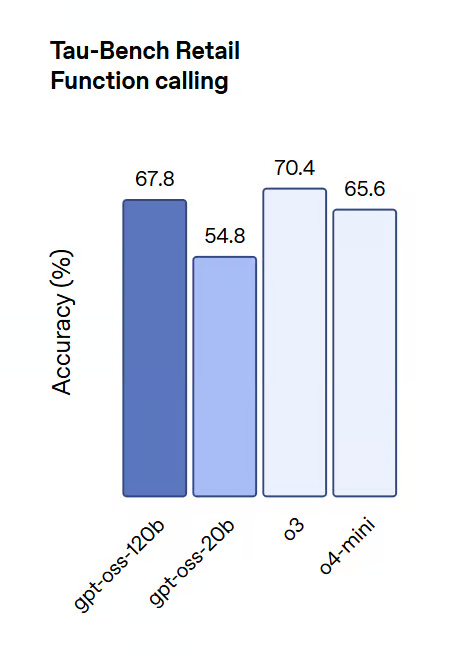
Image source: OpenAI
GPQA (PhD-Level Science Reasoning):
GPT-OSS-120B is competitive with o4-mini on advanced science reasoning tasks that particularly test deep domain knowledge, outperforming o3-mini and o3.
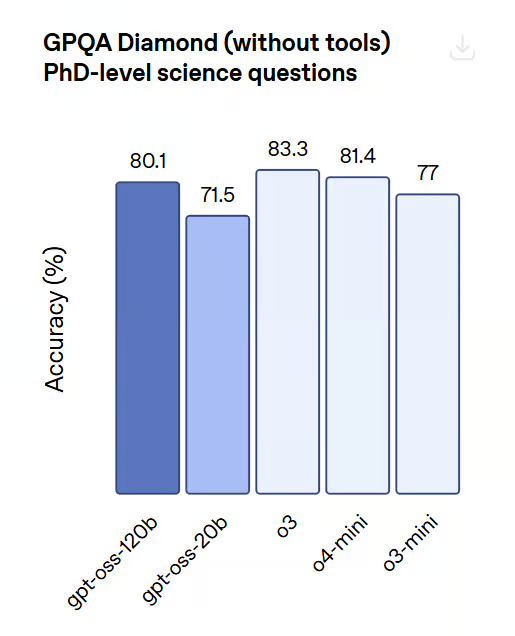
Image source: OpenAI

Image source: OpenAI
MMLU (Multi-Topic Academic Knowledge):
The models showed solid performance across MMLU categories.
GPT-OSS-120B achieved scores close to o4-mini, while GPT-OSS-20B surpassed o3-mini, demonstrating strength in general academic comprehension.
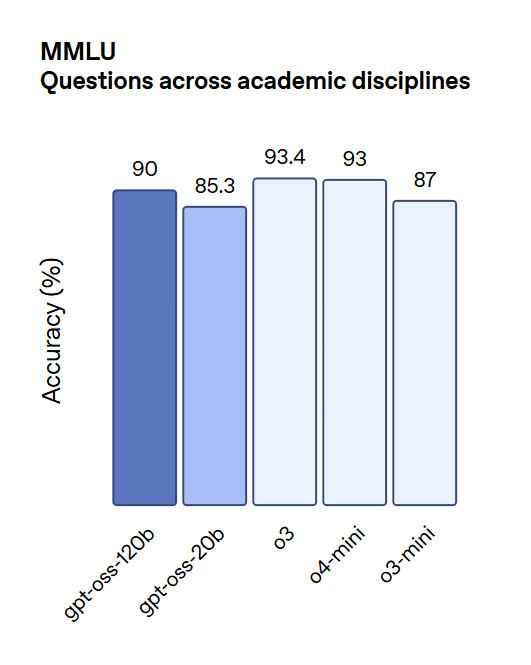
Image source: OpenAI
Safety Training and Adversarial Testing
Safety remains fundamental to OpenAI's approach, especially when releasing open models.
In addition to comprehensive safety training and evaluation, the team tested adversarially fine-tuned versions of GPT-OSS-120B according to the Preparedness Framework.
The model performed comparably to OpenAI's frontier systems on internal benchmarks, meeting the same safety standards as the latest proprietary models.
The evaluation methodology was reviewed by external experts, and the results shared through research papers and model cards represent important progress in setting new safety norms for open AI systems.
During pre-training, harmful data was filtered, including content related to chemical, biological, radiological, and nuclear (CBRN) threats.
Post-training used deliberative alignment and instruction hierarchy techniques to teach refusal of unsafe prompts, defend against prompt injection, and maintain ethical boundaries.
To simulate worst-case misuse scenarios, OpenAI fine-tuned adversarial versions of GPT-OSS models by mimicking potential attacker behavior on specialized biological and cybersecurity datasets.
These variants were tested according to the Preparedness Framework, and three independent expert groups reviewed the methodology.
The models did not reach high-risk capability thresholds, supporting their public release.
Testing methods and recommendations can be found in the safety white paper and model cards.
To encourage community-driven safety research and contribute to a safer open-source ecosystem, OpenAI launched a red-teaming challenge with $500,000 in prizes.
Researchers, developers, and enthusiasts are invited to find new vulnerabilities.
Once the challenge concludes, results will be made public and open-sourced.
To learn more or participate, visit OpenAI's official website.
Deployment and Availability
The models are now available for free download on Hugging Face and are provided quantized in MXFP4 for efficient deployment.
- GPT-OSS-120B runs within 80GB.
- GPT-OSS-20B runs within 16GB.
To help with integration, OpenAI is releasing both the Harmony prompt format and Harmony renderer (available in Python and Rust), along with inference references for PyTorch and Apple Metal and a sample toolkit for easier adoption.
Deployment partners ahead of launch include Azure, Hugging Face, Ollama, vLLM, AWS, Together AI, Databricks, Cloudflare, and more.
On the hardware side, OpenAI collaborated with industry leaders including NVIDIA, AMD, Cerebras, and Groq to optimize model performance across diverse deployment environments.
OpenAI also worked with early adopters including AI Sweden, Orange, and Snowflake to explore real-world applications of the open models.
These use cases range from on-premises deployment for data security to fine-tuning on specialized datasets.
By providing best-in-class open models alongside API hosting options, OpenAI aims to give everyone from individual developers to enterprises and governments the flexibility to run and customize AI on their own infrastructure.
Additionally, Microsoft supports GPU-optimized GPT-OSS-20B inference on Windows devices through the ONNX Runtime, available in Foundry Local and the AI Toolkit for VS Code.
For developers who need multimodal support, built-in tools, or tighter integration with the OpenAI platform, proprietary models accessed via API remain the best fit.
OpenAI has stated that it is listening to developer feedback and may consider API support for GPT-OSS in the future.
Developers can explore the models in OpenAI's Open Model Playground and access detailed guides for using various ecosystem providers or fine-tuning the models.
Why Open Models Matter
OpenAI describes GPT-OSS-120B and GPT-OSS-20B as milestones in delivering powerful open models that balance capability, safety, and customization.
They complement hosted models by offering high-performance, self-hosted options especially for developers with infrastructure constraints.
This release supports the broader goal of AI democratization, particularly for emerging markets, research labs, and government applications.
By enabling flexible deployment and fine-tuning, OpenAI aims to accelerate new advances across multiple fields while advancing transparency and alignment research.
Q&A
Q: What are GPT-OSS-120B and GPT-OSS-20B?
A: They are two open-weight language models from OpenAI, optimized for reasoning, tool use, and efficient deployment.
Q: How do they compare to proprietary models like GPT-4o or o3-mini?
A: They show comparable or better performance on benchmarks in math, health, and coding, especially with tool use enabled.
Q: What kind of hardware is required?
A: GPT-OSS-120B runs on a single 80GB GPU, and GPT-OSS-20B runs on 16GB, making it suitable for local or on-device inference.
Q: What safety measures were taken before release?
A: OpenAI conducted robust safety evaluations including adversarial fine-tuning, and external experts reviewed the results.
Q: Where can developers get the models and supporting tools?
A: The models are available on Hugging Face along with open-source tokenizers, renderers, and deployment references.
Implications
By releasing GPT-OSS-120B and GPT-OSS-20B, OpenAI is setting a new standard for open-weight model capabilities and responsible deployment.
These models lower the barrier to entry for developers worldwide by providing customizable, high-performance tools that rival proprietary systems.
With the GPT-OSS release, OpenAI now offers both closed and open models at levels that can compete with other cutting-edge systems.
This dual approach gives developers, enterprises, and governments more choices in how they access, deploy, and fine-tune AI, whether they prefer hosted APIs or self-managed infrastructure.
As AI infrastructure becomes more distributed and diverse, accessible models like GPT-OSS can enable new advances to flourish beyond cloud platforms.
This release reinforces the value of a healthy open-source ecosystem where safety, performance, and transparency can grow together.
By offering top-tier open models alongside its proprietary lineup, OpenAI is expanding the scope of what can be built with cutting-edge AI and where it can be built.
IMPAKERS Blog | GPT-5 Launch and ChatGPT Ad Integration Preview? Read More
Source: Alicia Shapiro, AiNews, "OpenAI Releases GPT-OSS-120B & GPT-OSS-20B as Open-Weight Language Models", https://www.ainews.com/p/openai-releases-gpt-oss-120b-gpt-oss-20b-as-open-weight-language-models, (2025. 8. 5)