AI 이슈: 스파이킹브레인 AI 모델 공개

이미지 출처: ChatGPT-5
두뇌에서 영감을 얻은 AI의 새로운 발전
핵심 내용
- 스파이킹브레인 1.0은 사람의 뇌가 정보를 처리하는 방식을 따라 했어요. 필요할 때만 활성화되는 스파이킹 뉴런을 써서 더 효율적으로 동작하죠.
- 연구진들은 기존 AI 시스템에서 쓰는 데이터의 2%도 안 되는 양으로 7B와 76B 매개변수 모델을 학습시켰어요.
- 7B 모델은 일반적인 모델보다 100배 빠른 속도로 400만 개의 토큰 프롬프트를 처리했답니다.
- 두 모델 모두 전부 MetaX GPU에서만 학습하고 테스트했어요. 이건 중국이 NVIDIA 없이도 고급 AI를 만들 수 있다는 걸 보여주는 거죠.
- "Shunxi"라는 공개 데모를 통해 누구나 온라인에서 SpikingBrain 모델을 직접 써볼 수 있어요.
SpikingBrain: 뇌에서 영감을 얻은 새로운 대안 모델
베이징의 한 연구팀이 사람의 뇌가 작동하는 방식을 더 가깝게 따라하도록 설계된 AI 시스템인 SpikingBrain 1.0을 공개했어요.
요즘의 거대 언어 모델(LLM)처럼 모든 뉴런을 '켜진 상태'로 계속 유지하는 대신, SpikingBrain 뉴런은 꼭 필요할 때만 활성화돼요.
이런 접근법은 하이브리드 주의 메커니즘과 전문가 혼합(MoE) 확장과 결합되어서 시스템을 훨씬 빠르고 효율적으로 만들어 줍니다.
연구진은 비용과 데이터, 하드웨어 가용성이 중요한 관심사가 된 지금 시점에서 거대 언어 모델에 대한 새로운 방향을 제시한다고 말해요.
더 적은 데이터로 더 빠른 속도를 보여주는 학습
SpikingBrain은 두 가지 버전으로 나왔어요.
효율성을 위해 설계된 더 작은 SpikingBrain-7B와 정확도를 높이기 위해 만든 더 큰 SpikingBrain-76B가 바로 그것이죠.
두 모델 모두 최신 언어 모델에 보통 쓰이는 데이터의 2%도 안 되는 약 1,500억 개의 토큰으로 학습했어요.
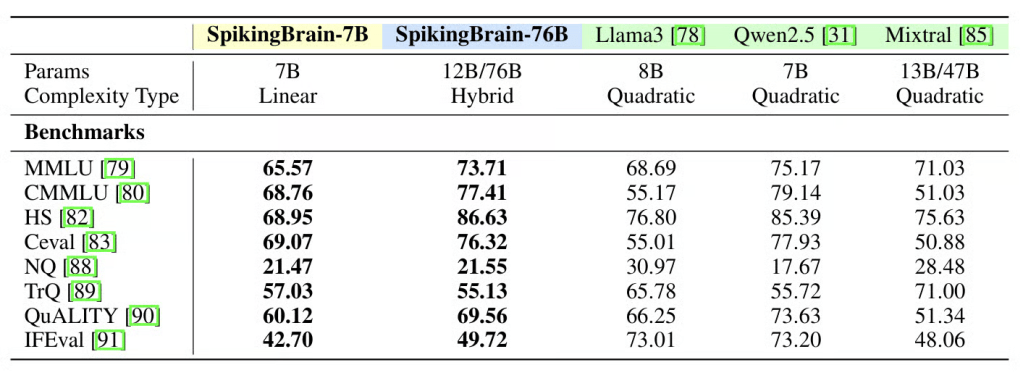
이렇게 훨씬 가벼운 학습 부하에도 불구하고 두 모델은 평가에서 많은 기존 시스템과 비슷하거나 더 나은 성능을 보였답니다.
SpikingBrain-7B는 효율성에 중점을 둔 모델이에요.
토큰마다 더 적은 수의 매개변수를 활성화하기 때문에 입력이 아주 긴 작업에 특히 좋아요.
테스트 결과를 보면, 4백만 개의 토큰 프롬프트를 일반적인 트랜스포머 모델보다 100배 이상 빠르게 처리하면서도 몇 주 동안 안정성을 유지했어요.
MMLU, CMMLU, ARC-C, 헬라스와그, C-Eval 같은 벤치마크에서 7B 모델은 학습 데이터의 일부만 사용하면서도 기준 트랜스포머 시스템의 약 90% 성능을 회복했답니다.

더 큰 SpikingBrain-76B는 하이브리드 전문가 혼합 구조를 써서 복잡성은 늘어나지만 정확도는 계속 향상돼요.
이 모델은 상위 트랜스포머 모델과의 격차를 상당 부분 좁혔고, 경우에 따라서는 Llama2-70B, Mixtral-8×7B, Gemma2-27B 같이 널리 쓰이는 시스템과 맞먹거나 뛰어넘기도 했어요.

수치로 보는 SpikingBrain의 성능과 효율성
- 150억 개의 토큰 - 두 모델에 사용된 학습 데이터로, 보통의 최신 LLM 데이터 세트의 2% 미만이에요.
- 100배 빨라진 속도 - 4백만 토큰 프롬프트에서 첫 번째 토큰에 도달하는 시간이 SpikingBrain-7B로 100배 빨라졌어요.
- 90% 벤치마크 회복 - 7B 모델은 MMLU, CMMLU, ARC-C, 헬라스와그, C-Eval에서 기준 트랜스포머 성능의 ~90%에 도달했답니다.
- 수백 개의 MetaX C550 GPU - 학습에 쓰인 하드웨어로, NVIDIA 생태계 밖에서도 대규모 안정성을 보여줬어요.
하드웨어 독립성: MetaX 칩에서 실행되는 시스템
가장 눈에 띄는 성과 중 하나는 연구원들이 NVIDIA 하드웨어가 아닌 수백 대의 중국 MetaX C550 GPU로만 SpikingBrain을 학습시켰다는 점이에요.
이를 위해 연구진은 연산자 라이브러리와 병렬 처리 전략, 메모리 최적화를 MetaX에 맞게 맞춤화했어요.
연구팀은 몇 주에 걸친 안정적인 대규모 학습을 보고하면서 이제 고급 거대 언어 모델을 NVIDIA 생태계 밖에서도 만들고 배포할 수 있다는 걸 강조했어요.
이런 독립성은 칩 공급망과 국가 기술 독립성에 대한 지속적인 걱정을 생각할 때 특히 중요해요.
일반 사용자도 써볼 수 있는 순시 데모
연구진은 진행 상황을 보여주기 위해 더 작은 SpikingBrain-7B 모델을 깃허브를 통해 오픈 소스로 공개했어요.
이를 통해 개발자와 연구자들은 시스템을 연구하고 효율성에 초점을 맞춘 설계를 바탕으로 더 발전시킬 수 있는 기회를 얻게 됐어요.
또한, 더 큰 시스템의 기능을 보여주기 위해 주력 제품인 SpikingBrain-76B의 공개 데모인 Shunxi도 소개했어요.
7B 릴리즈와는 다르게 Shunxi는 오픈 소스는 아니지만 사용자가 모델의 성능을 직접 체험할 수 있는 온라인 체험판을 제공해요.
연구 논문에서는 데모를 쓸 수 있다고 언급하고 있지만 영구적인 링크는 제공하지 않아요.
이 모델은 SpikingBrain의 성능뿐만 아니라 국내 인프라에서 완벽하게 작동하는 능력도 보여줘요.
SpikingBrain에 대해 더 알아보기
Q: SpikingBrain이 다른 AI 모델과 다른 점은 무엇인가요?
꼭 필요할 때만 활성화되는 스파이킹 뉴런을 써서 사람의 뇌가 작동하는 방식과 비슷하게 더 빠르고 효율적으로 동작해요.
Q: 얼마나 많은 학습 데이터를 썼나요?
약 1,500억 개의 토큰으로, 대부분의 거대 모델에 필요한 데이터의 2% 미만이에요.
Q: 기존 AI 시스템과 비교했을 때 얼마나 빠른가요?
더 작은 7B 모델은 일반적인 시스템보다 100배 빠른 속도로 4백만 개의 토큰 프롬프트를 처리했어요.
Q: 어떤 하드웨어에서 돌아가나요?
NVIDIA 칩을 쓰지 않고 전부 중국의 MetaX GPU에서만 학습하고 테스트했어요.
Q: 일반인도 SpikingBrain을 써볼 수 있나요?
네, 가능해요. 더 작은 SpikingBrain-7B는 GitHub에서 오픈 소스로 제공돼요.
더 큰 SpikingBrain-76B의 경우, 팀에서 Shunxi라는 공개 데모를 출시했어요.
연구 논문에서 사용 가능 여부를 확인할 수 있지만 영구 링크는 제공하지 않아요.
시사점
SpikingBrain의 출시는 세 가지 중요한 변화를 보여줘요:
규모보다 효율성이 중요해요
뇌에서 영감을 받은 설계는 성능 향상을 위해 항상 더 큰 데이터 세트나 더 높은 비용이 필요한 건 아니라는 걸 보여줍니다.
하드웨어 다양화가 진행돼요
MetaX GPU가 고급 모델을 돌릴 수 있다는 걸 입증함으로써 중국은 서구 칩 제조업체에 대한 의존도를 줄이고 있어요.
전 세계적인 경쟁이 치열해져요
여러 나라가 자체 AI 시스템과 하드웨어를 만들면서 환경이 더욱 다양해지고 경쟁이 치열해지고 있어요.
이런 새로운 발전은 더 빠르고 저렴하며 에너지 효율적인 시스템을 약속하면서, 거대 언어 모델을 만드는 방식과 장소를 다시 바꿔놓고 있어요.
임패커스 블로그 | 마이크로소프트 오피스365 클로드 소넷4 도입 예고? 더 보러가기
출처: Alicia Shapiro, AiNews, "China’s New SpikingBrain AI Models Deliver Speed and Efficiency on Domestic Chips", https://www.ainews.com/p/china-s-new-spikingbrain-ai-models-deliver-speed-and-efficiency-on-domestic-chips, (2025-09-15)