Tema IA: Nuevo modelo de OpenAI GPT-OSS

OpenAI lanza GPT-OSS-120B y GPT-OSS-20B como modelos de lenguaje de pesos abiertos
Puntos clave
- OpenAI ha lanzado dos nuevos modelos de lenguaje de pesos abiertos, GPT-OSS-120B y GPT-OSS-20B, disponibles bajo la licencia Apache 2.0.
- Estos modelos igualan o superan el rendimiento de sistemas propietarios como GPT-4o, o3-mini y o4-mini en benchmarks como HealthBench, AIME y TauBench.
- GPT-OSS-120B funciona en una sola GPU de 80GB, mientras que el mas pequeno GPT-OSS-20B opera en dispositivos edge con solo 16GB de memoria.
- Los modelos soportan uso de herramientas, razonamiento de Cadena de Pensamiento (CoT), salidas estructuradas y esfuerzo de razonamiento ajustable para equilibrios entre latencia y rendimiento.
- OpenAI realizo evaluaciones de seguridad exhaustivas incluyendo revisiones de expertos independientes y ajuste fino segun el Marco de Preparacion.
OpenAI lanza modelos GPT-OSS para avanzar el desarrollo de IA abierta
Algo verdaderamente importante ha ocurrido en OpenAI.
Han lanzado dos nuevos modelos de lenguaje de pesos abiertos, GPT-OSS-120B y GPT-OSS-20B, disponibles para cualquier persona bajo la licencia Apache 2.0.
Estos modelos estan especializados en tareas de razonamiento, uso de herramientas y despliegue eficiente en costos.
Estan especificamente disenados para funcionar bien en hardware de consumo, son completamente personalizables y soportan salidas estructuradas.
GPT-OSS-120B ofrece un rendimiento cercano a o4-mini en benchmarks de razonamiento mientras opera en una sola GPU de 80GB.
GPT-OSS-20B logra resultados comparables a o3-mini mientras requiere solo 16GB de memoria, siendo perfecto para inferencia local o en dispositivo.
Estos modelos superaron a otros sistemas abiertos en tareas complejas.
GPT-OSS-120B destaca particularmente en uso de herramientas, llamadas a funciones y razonamiento de Cadena de Pensamiento (CoT).
En la metrica HealthBench, incluso supero a modelos propietarios como o1 y GPT-4o.
Ademas, se integra perfectamente con la API de Respuestas de OpenAI y soporta flujos de trabajo agenticos con un seguimiento de instrucciones sobresaliente.
La intensidad de razonamiento tambien puede ajustarse segun los requisitos de latencia.
Arquitectura del Modelo y Rendimiento
OpenAI entreno los modelos GPT-OSS usando tecnicas de pre-entrenamiento y post-entrenamiento de ultima generacion, centrandose en razonamiento, eficiencia y utilidad practica en diversos entornos de despliegue.
Aunque previamente habian liberado como codigo abierto modelos como Whisper y CLIP, este es el primer modelo de lenguaje de pesos abiertos desarrollado desde GPT-2.
Cada modelo utiliza una arquitectura Transformer con un diseno de Mezcla de Expertos (MoE) que activa solo una fraccion de parametros por token para mejorar la eficiencia.
| Modelo | Parametros Totales | Parametros Activos | Capas | Expertos | Expertos Activos | Longitud de Contexto |
|---|---|---|---|---|---|---|
| GPT-OSS-120B | 117B | 5.1B | 36 | 128 | 4 | 128k |
| GPT-OSS-20B | 21B | 3.6B | 24 | 32 | 4 | 128k |
Para mejorar aun mas la eficiencia de inferencia y memoria, ambos modelos alternan entre patrones de atencion dispersa de alta densidad y banda local (similar a GPT-3) y patrones de atencion multi-consulta agrupada con un tamano de grupo de 8.
Se utilizan Embeddings de Posicion Rotativa (RoPE) para la codificacion posicional.
Estos modelos soportan una longitud maxima de contexto de 128,000 tokens.
Fueron entrenados con un conjunto de datos principalmente en ingles y solo texto, con fuerte representacion en STEM, programacion y conocimiento general.
La tokenizacion se realizo usando un nuevo tokenizador o200k_harmony que se libera como codigo abierto junto con este lanzamiento.
La informacion detallada se puede encontrar en las tarjetas del modelo.
Post-Entrenamiento y Control de Razonamiento
El post-entrenamiento siguio los mismos metodos utilizados para o4-mini de OpenAI, incluyendo ajuste fino supervisado y etapas de aprendizaje por refuerzo (RL).
Los modelos estan alineados con la Especificacion del Modelo de OpenAI, soportando razonamiento en cadena de pensamiento, uso de herramientas y seguimiento de instrucciones.
Al aplicar las mismas tecnicas utilizadas en los modelos de razonamiento propietarios de ultima generacion de OpenAI, los modelos GPT-OSS demuestran un fuerte rendimiento post-entrenamiento en tareas de razonamiento.
Al igual que la serie propietaria o de OpenAI, estos modelos ofrecen modos de razonamiento bajo, medio y alto.
Esto permite a los desarrolladores optimizar la latencia o el rendimiento ajustando el parametro del mensaje del sistema.
Resultados de las Pruebas
GPT-OSS-120B y GPT-OSS-20B fueron probados en benchmarks academicos estandar para evaluar capacidades de programacion, matematicas competitivas, razonamiento relacionado con la salud y uso de herramientas agenticas.
En estas evaluaciones, los modelos igualaron o superaron consistentemente los modelos de razonamiento propietarios de OpenAI, incluyendo o3, o3-mini y o4-mini.
Codeforces (Programacion Competitiva):
GPT-OSS-120B logro una calificacion Elo superior a o3-mini y un rendimiento comparable a o4-mini, demostrando resultados solidos en tareas de programacion competitiva.
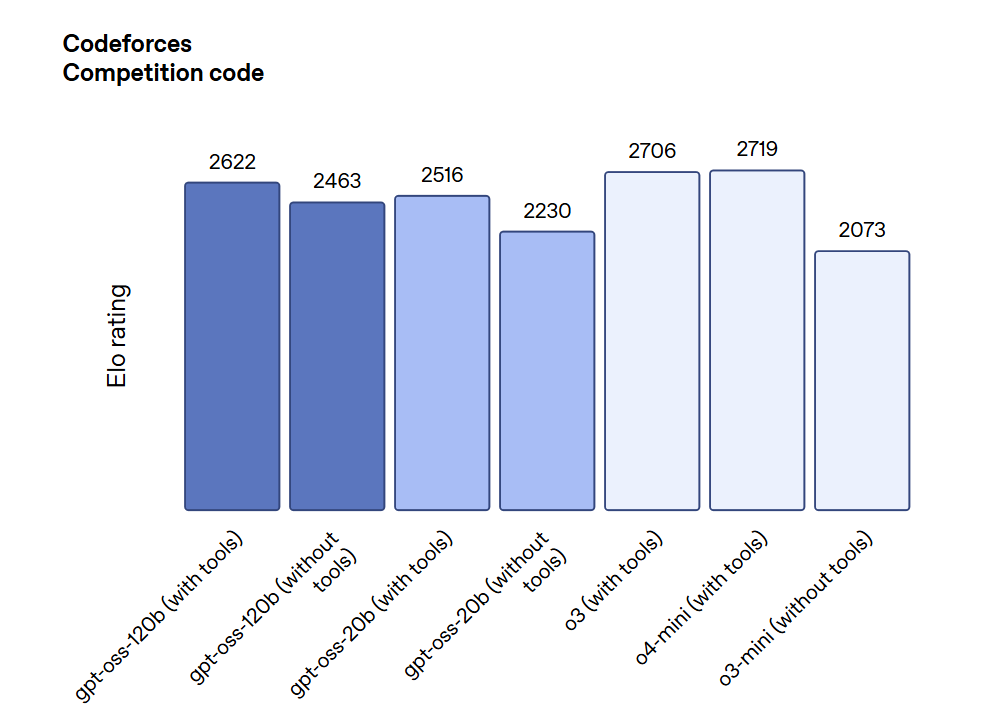
Fuente de imagen: OpenAI
Problemas de Nivel Experto en Multiples Dominios:
En este benchmark que prueba habilidades de razonamiento en varios dominios academicos de nivel experto, GPT-OSS-120B y GPT-OSS-20B mostraron rendimiento competitivo, especialmente en escenarios asistidos por herramientas.
Aunque los modelos propietarios como o4-mini lideran en esta area, los modelos GPT-OSS aun entregaron resultados significativos en prompts altamente especializados, demostrando amplia aplicabilidad.
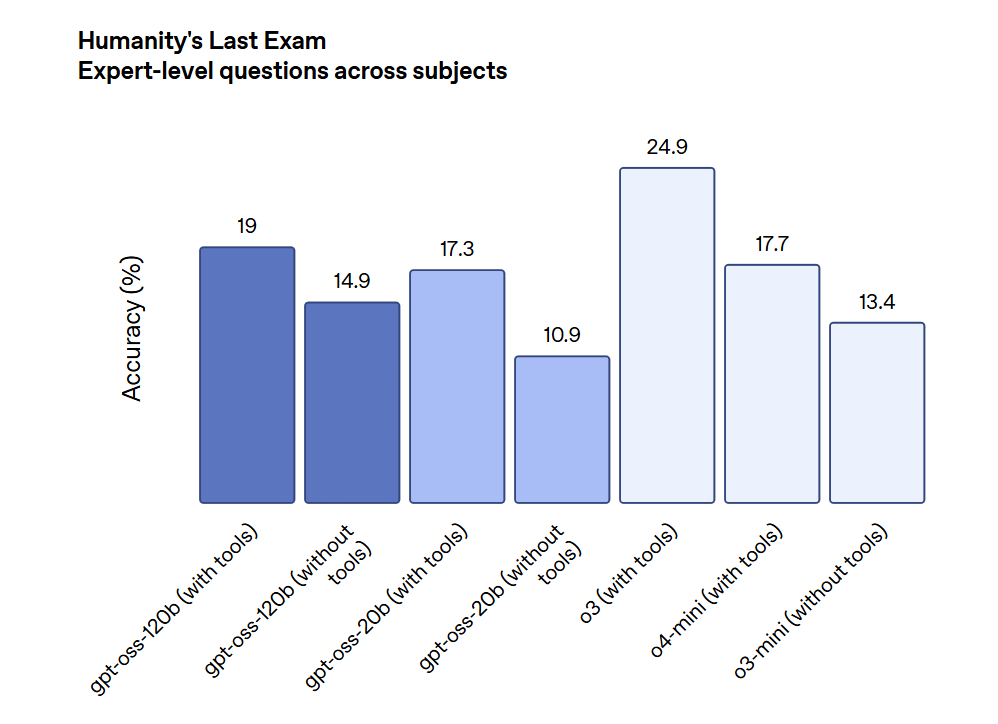
Fuente de imagen: OpenAI
Conversaciones sobre Salud y Medicina:
Tanto en evaluaciones estandar como dificiles, GPT-OSS-120B y GPT-OSS-20B superaron a GPT-4o, o3 y o3-mini, mostrando particular fortaleza en benchmarks de razonamiento relacionado con la salud.

Fuente de imagen: OpenAI
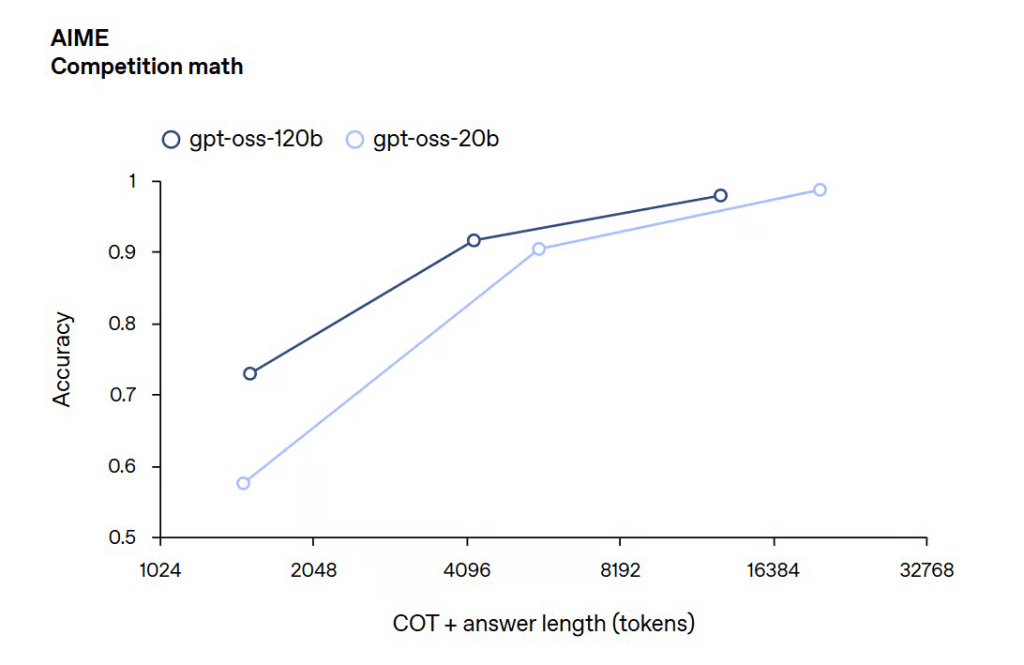
AIME 2024 y 2025 (Matematicas Competitivas):
Ambos modelos lograron alta precision, con GPT-OSS-120B puntuando 97.9% y GPT-OSS-20B puntuando 98.7% en AIME 2024.
En AIME 2025, ambos modelos superaron a o3-mini, y GPT-OSS-20B supero a o3 en ciertas tareas a pesar de su tamano menor.
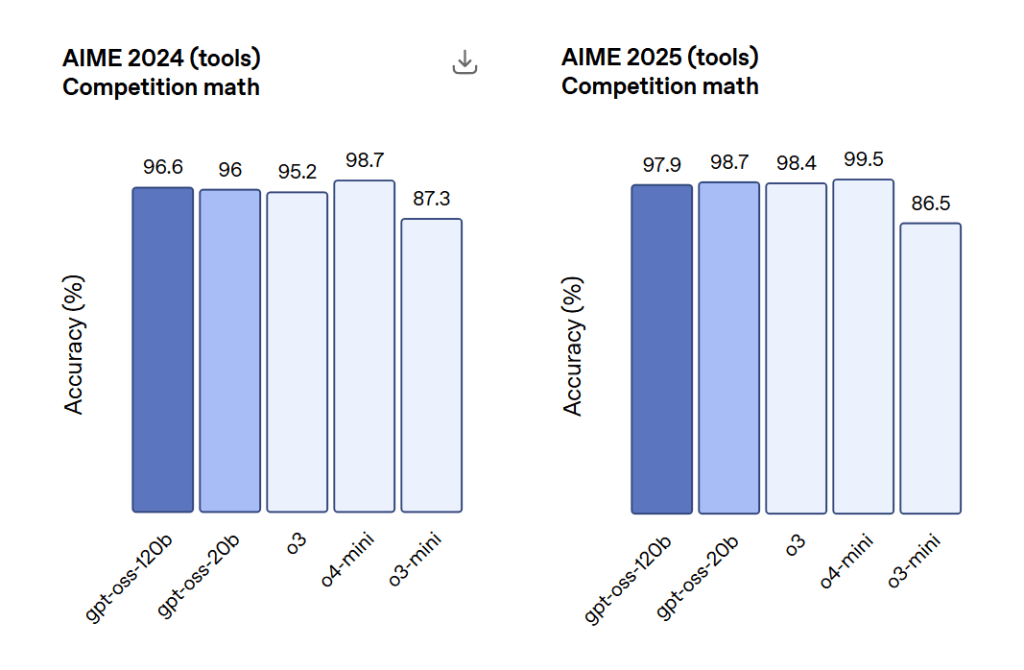
Fuente de imagen: OpenAI
Fuente de imagen: OpenAI
Tau-Bench (Uso de Herramientas y Llamadas a Funciones):
Los modelos demostraron un rendimiento solido en llamadas a funciones de pocos ejemplos, generacion de respuestas largas y razonamiento de Cadena de Pensamiento (CoT), siguiendo de cerca la precision de o4-mini y o3 en evaluaciones aumentadas con herramientas.
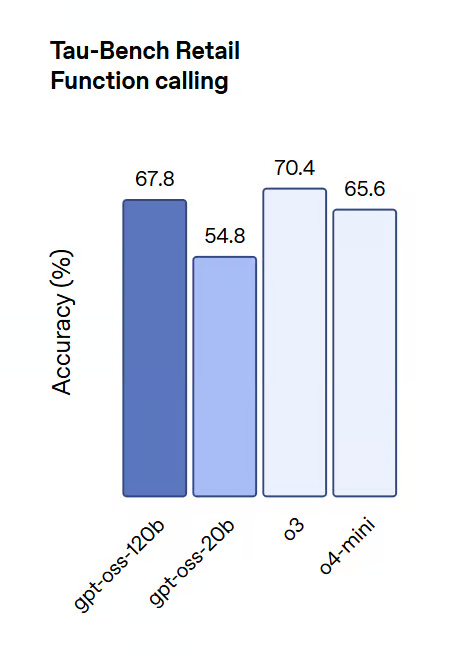
Fuente de imagen: OpenAI
GPQA (Razonamiento Cientifico de Nivel Doctorado):
GPT-OSS-120B es competitivo con o4-mini en tareas avanzadas de razonamiento cientifico que prueban particularmente el conocimiento profundo del dominio, superando a o3-mini y o3.
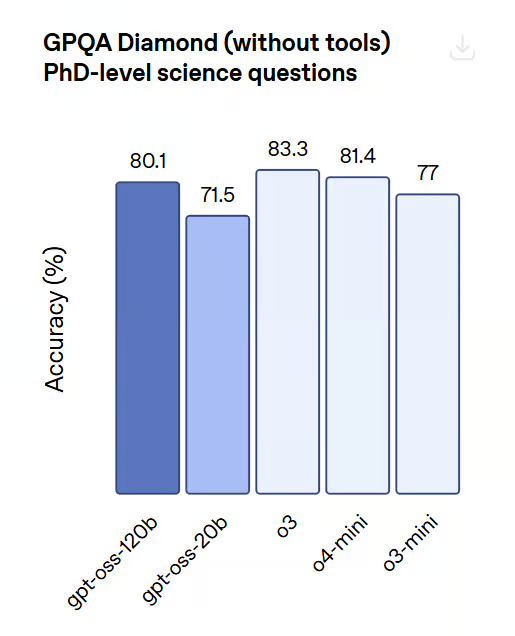
Fuente de imagen: OpenAI

Fuente de imagen: OpenAI
MMLU (Conocimiento Academico Multi-Tema):
Los modelos mostraron un rendimiento solido en todas las categorias de MMLU.
GPT-OSS-120B logro puntuaciones cercanas a o4-mini, mientras que GPT-OSS-20B supero a o3-mini, demostrando fortaleza en comprension academica general.
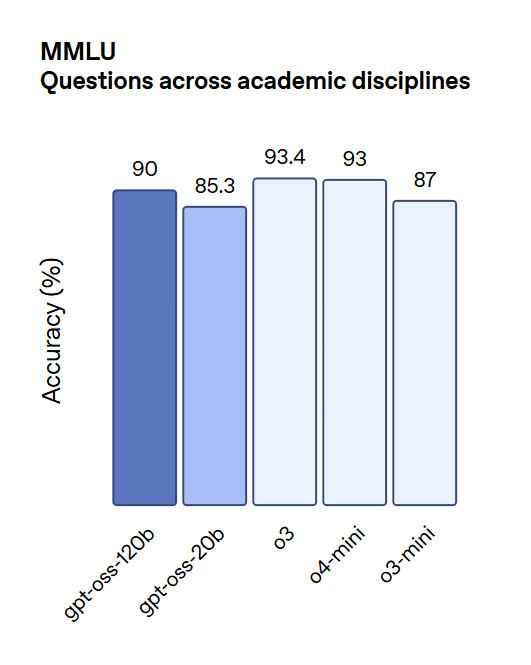
Fuente de imagen: OpenAI
Entrenamiento de Seguridad y Pruebas Adversariales
La seguridad sigue siendo fundamental en el enfoque de OpenAI, especialmente al lanzar modelos abiertos.
Ademas del entrenamiento y evaluacion de seguridad integral, el equipo probo versiones adversarialmente ajustadas de GPT-OSS-120B segun el Marco de Preparacion.
El modelo rindio de forma comparable a los sistemas frontera de OpenAI en benchmarks internos, cumpliendo los mismos estandares de seguridad que los ultimos modelos propietarios.
La metodologia de evaluacion fue revisada por expertos externos, y los resultados compartidos a traves de articulos de investigacion y tarjetas de modelo representan un avance importante en el establecimiento de nuevas normas de seguridad para sistemas de IA abiertos.
Durante el pre-entrenamiento, se filtraron datos daninos, incluyendo contenido relacionado con amenazas quimicas, biologicas, radiologicas y nucleares (QBRN).
El post-entrenamiento utilizo alineacion deliberativa y tecnicas de jerarquia de instrucciones para ensenar el rechazo de prompts inseguros, defenderse contra la inyeccion de prompts y mantener limites eticos.
Para simular los peores escenarios de uso indebido, OpenAI ajusto versiones adversariales de los modelos GPT-OSS imitando el comportamiento de posibles atacantes en conjuntos de datos especializados de biologia y ciberseguridad.
Estas variantes fueron probadas segun el Marco de Preparacion, y tres grupos independientes de expertos revisaron la metodologia.
Los modelos no alcanzaron umbrales de capacidad de alto riesgo, respaldando su publicacion.
Los metodos de prueba y recomendaciones se pueden encontrar en el libro blanco de seguridad y las tarjetas del modelo.
Para fomentar la investigacion de seguridad impulsada por la comunidad y contribuir a un ecosistema de codigo abierto mas seguro, OpenAI lanzo un desafio de red-teaming con $500,000 en premios.
Se invita a investigadores, desarrolladores y entusiastas a encontrar nuevas vulnerabilidades.
Una vez concluido el desafio, los resultados se haran publicos y se liberaran como codigo abierto.
Para obtener mas informacion o participar, visita el sitio web oficial de OpenAI.
Despliegue y Disponibilidad
Los modelos estan ahora disponibles para descarga gratuita en Hugging Face y se proporcionan cuantizados en MXFP4 para un despliegue eficiente.
- GPT-OSS-120B funciona dentro de 80GB.
- GPT-OSS-20B funciona dentro de 16GB.
Para ayudar con la integracion, OpenAI esta lanzando tanto el formato de prompt Harmony como el renderizador Harmony (disponible en Python y Rust), junto con referencias de inferencia para PyTorch y Apple Metal y un kit de herramientas de muestra para una adopcion mas facil.
Los socios de despliegue antes del lanzamiento incluyen Azure, Hugging Face, Ollama, vLLM, AWS, Together AI, Databricks, Cloudflare y mas.
En el lado del hardware, OpenAI colaboro con lideres de la industria incluyendo NVIDIA, AMD, Cerebras y Groq para optimizar el rendimiento del modelo en diversos entornos de despliegue.
OpenAI tambien trabajo con adoptadores tempranos incluyendo AI Sweden, Orange y Snowflake para explorar aplicaciones del mundo real de los modelos abiertos.
Estos casos de uso van desde el despliegue local para seguridad de datos hasta el ajuste fino en conjuntos de datos especializados.
Al proporcionar modelos abiertos de primera clase junto con opciones de alojamiento API, OpenAI tiene como objetivo dar a todos, desde desarrolladores individuales hasta empresas y gobiernos, la flexibilidad para ejecutar y personalizar IA en su propia infraestructura.
Ademas, Microsoft soporta la inferencia de GPT-OSS-20B optimizada para GPU en dispositivos Windows a traves del ONNX Runtime, disponible en Foundry Local y el AI Toolkit para VS Code.
Para desarrolladores que necesitan soporte multimodal, herramientas integradas o una integracion mas estrecha con la plataforma OpenAI, los modelos propietarios accesibles via API siguen siendo la mejor opcion.
OpenAI ha declarado que esta escuchando los comentarios de los desarrolladores y podria considerar el soporte API para GPT-OSS en el futuro.
Los desarrolladores pueden explorar los modelos en el Playground de Modelos Abiertos de OpenAI y acceder a guias detalladas para usar varios proveedores del ecosistema o ajustar los modelos.
Por Que Importan los Modelos Abiertos
OpenAI describe GPT-OSS-120B y GPT-OSS-20B como hitos en la entrega de modelos abiertos potentes que equilibran capacidad, seguridad y personalizacion.
Complementan los modelos alojados al ofrecer opciones de alto rendimiento auto-alojadas, especialmente para desarrolladores con restricciones de infraestructura.
Este lanzamiento apoya el objetivo mas amplio de democratizacion de la IA, particularmente para mercados emergentes, laboratorios de investigacion y aplicaciones gubernamentales.
Al permitir un despliegue flexible y ajuste fino, OpenAI tiene como objetivo acelerar nuevos avances en multiples campos mientras avanza en transparencia e investigacion de alineacion.
Preguntas y Respuestas
P: Que son GPT-OSS-120B y GPT-OSS-20B?
R: Son dos modelos de lenguaje de pesos abiertos de OpenAI, optimizados para razonamiento, uso de herramientas y despliegue eficiente.
P: Como se comparan con modelos propietarios como GPT-4o u o3-mini?
R: Muestran un rendimiento comparable o mejor en benchmarks de matematicas, salud y programacion, especialmente con el uso de herramientas habilitado.
P: Que tipo de hardware se necesita?
R: GPT-OSS-120B funciona en una sola GPU de 80GB, y GPT-OSS-20B funciona con 16GB, siendo adecuado para inferencia local o en dispositivo.
P: Que medidas de seguridad se tomaron antes del lanzamiento?
R: OpenAI realizo evaluaciones de seguridad robustas incluyendo ajuste fino adversarial, y expertos externos revisaron los resultados.
P: Donde pueden los desarrolladores obtener los modelos y herramientas de soporte?
R: Los modelos estan disponibles en Hugging Face junto con tokenizadores de codigo abierto, renderizadores y referencias de despliegue.
Implicaciones
Al lanzar GPT-OSS-120B y GPT-OSS-20B, OpenAI esta estableciendo un nuevo estandar para las capacidades de modelos de pesos abiertos y el despliegue responsable.
Estos modelos reducen la barrera de entrada para desarrolladores de todo el mundo al proporcionar herramientas personalizables de alto rendimiento que rivalizan con los sistemas propietarios.
Con el lanzamiento de GPT-OSS, OpenAI ahora ofrece tanto modelos cerrados como abiertos a niveles que pueden competir con otros sistemas de vanguardia.
Este enfoque dual da a desarrolladores, empresas y gobiernos mas opciones en como acceden, despliegan y ajustan la IA, ya sea que prefieran APIs alojadas o infraestructura autogestionada.
A medida que la infraestructura de IA se vuelve mas distribuida y diversa, modelos accesibles como GPT-OSS pueden permitir que nuevos avances florezcan mas alla de las plataformas en la nube.
Este lanzamiento refuerza el valor de un ecosistema de codigo abierto saludable donde la seguridad, el rendimiento y la transparencia pueden crecer juntos.
Al ofrecer modelos abiertos de primer nivel junto con su linea propietaria, OpenAI esta expandiendo el alcance de lo que se puede construir con IA de vanguardia y donde se puede construir.
Blog IMPAKERS | Lanzamiento de GPT-5 y Prevision de Integracion de Anuncios en ChatGPT? Leer mas
Source: Alicia Shapiro, AiNews, "OpenAI Releases GPT-OSS-120B & GPT-OSS-20B as Open-Weight Language Models", https://www.ainews.com/p/openai-releases-gpt-oss-120b-gpt-oss-20b-as-open-weight-language-models, (2025. 8. 5)